WGU Capstone
Scenario
An educational agency intends to develop an application that predicts graduate school admission chances using a deep learning process. By estimating these chances for its students, the agency enables them to set more informed goals. The application should take inputs such as University Rating, Letter of Recommendation Strength, and Research Experience to predict the likelihood of admission.
However, the agency encountered a challenge: crucial columns—namely, GRE Scores, Undergraduate GPA, and TOEFL Scores—were absent from their dataset. Fortunately, the educational agency still possesses old survey data—namely, Average Daily Study Hours, English Self-Confidence Scale, Address (proximity), and Age—that may correlate with the admission chances. By leveraging State Knowledge Graph (SKG) of the data, a Large Language Model (LLM) will recommend adding new columns that probably align with the admission chances. This addition is expected to enhance the deep learning process.
During the evaluation phase, we will assess how the deep-learning predictions perform with the newly suggested columns of data compared to their performance without it.
Dataset
Content
The dataset has different important things that are needed when applying for Master's programs.
These things include:
Source
https://www.kaggle.com/datasets/mohansacharya/graduate-admissions
Acharya, M. S., Armaan, A., & Antony, A. S. (2019, February). A comparison of regression models for prediction of graduate admissions. In 2019 international conference on computational intelligence in data science (ICCIDS) (pp. 1-5). IEEE.
Deep learning trial 1: training Artificial Neural Network (ANN) with missing data
The scnerio dictates the input data for deep learning are missing three important columns: GRE Scores, Undergraduate GPA, and TOEFL Scores.
Before we enhance our data by leveraging SKG later, let's see how the admission prediction model with these missing data performs for the comparison.
ChatGPT analyzes SKG: expanding connections
Now that we have seen how the prediction model with the missing data performs, the next step is to include data to the dataset that may help the model perform better.
According to the scenario, in addition to the original dataset, there are old surveys that include information about Average Daily Study Hours, English Self-Confidence Scale, Address (proximity), and Age. Each student answered these surveys.
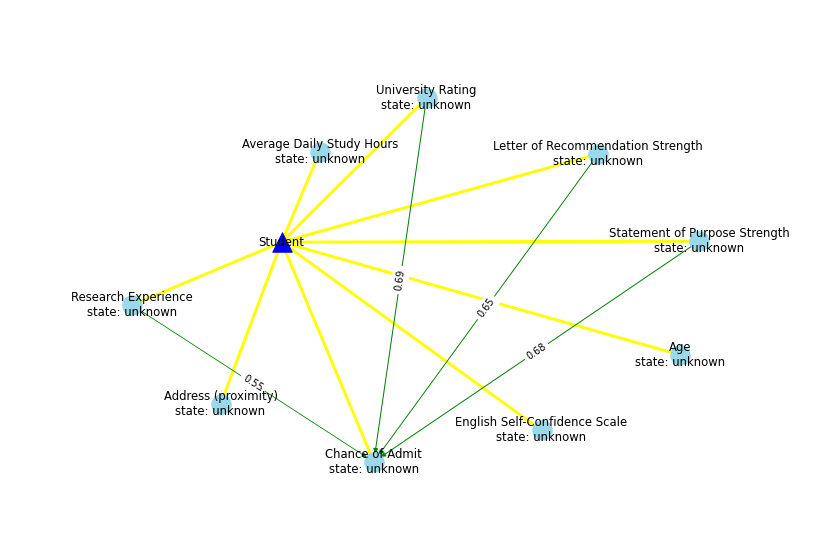
Let's see the current SKG, then ask ChatGPT to expand connections in such SKG.
SKG with the missing data
Result:
Ask ChatGPT
ChatGPT answer
Try it yourself:
1. Remove lines of ChatGPT's previous response between "=== what LLM suggests Start ===" and "=== what LLM suggests End ===" in the following code.
2. Copy and paste a new response generated by you (ChatGPT often gives different answers each time) into the previous response's place.
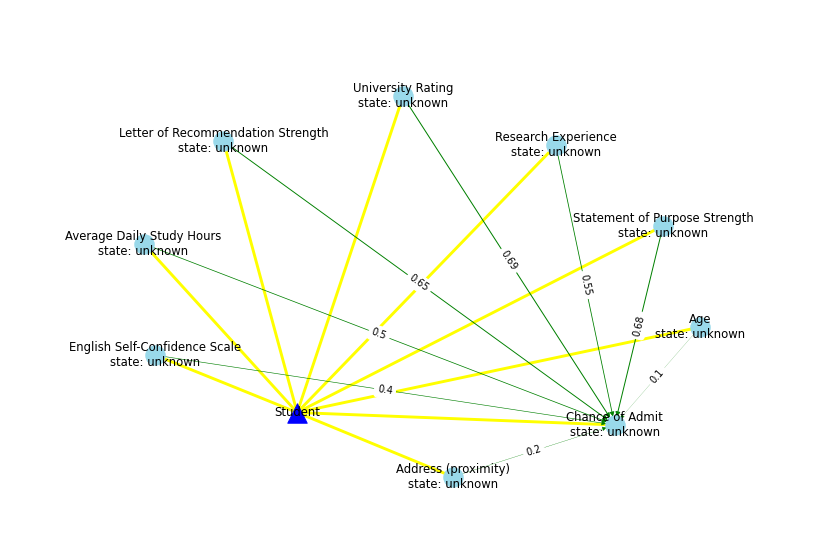
SKG with the expanded connections
Result:
Deep learning trial 2: training ANN with a reinforced dataset
Now that the expanded SKG has suggested that "Average Daily Study Hours" and "English Self-Confidence Scale" (among other survey data) may have the strongest correlations with admission chances, let's add those variables to the dataset.
Since the scenario "Fortunately, there was survey data that were answered by each student" is hypothetical, we need to create new data for "Average Daily Study Hours" and "English Self-Confidence Scale". Based on the missing data, new columns have been created/added to the dataset: "Average Daily Study Hours" has a Pearson product-moment correlation coefficient of 0.94 with Undergraduate GPA and 0.79 with GRE Scores, while "English Self-Confidence Scale" has a correlation coefficient of 0.96 with TOEFL Scores. Note that while these correlation coefficients are arbitrary values, they are derived from the "missing" data because it is only natural that if you study more, your grades will likely improve, and if you're confident in English, you'll likely achieve a better English test score.
Evaluation: Deep learning trial 1 vs trial 2
| Deep Learning Trial | MAE | MSE | RMSE | Variance Regression Score |
|---|---|---|---|---|
| Trial 1 | 0.061997806525230396 | 0.00720333908910754 | 0.08487248723295164 | 0.6707320647852236 |
| Trial 2 | 0.04799928128719329 | 0.004544161076868883 | 0.06741039294403263 | 0.7863313792402611 |
Conclusion
We have achieved a better prediction model by leveraging SKG. In this case, the SKG was quite simple, consisting of only one object node with several states. We could easily expand connections in the SKG ourselves.
However, in reality, many things are interconnected in complex ways, and sometimes the right solutions don't immediately surface. For instance, if you're unable to use your car for an appointment, SKG could suggest considering alternative transportation options such as a taxi or flight, or even postponing the appointment.
SKG is a useful structure that helps identify meaningful connections in the environment (see Advantage of SKG 1: expanding connections).
The application: predict your admission chance
It is based on the trained model from Deep learning trial 2.
Result: